
LOESS is more
Dit artikel behandelt het creëren van een trendlijn met behulp van de LOESS-methode, zoals toegepast door het KNMI. Besproken wordt hoe LOESS in Python kan worden toegepast.
Lees ook het vervolg artikel From SMA to LOESS waarin ook de wiskunde achter deze methode wordt beschreven en uitgelegd
LOESS, wat staat voor “Locally Estimated Scatterplot Smoothing,” is een niet-parametrische regressiemethode die vaak wordt gebruikt om relaties tussen variabelen in een dataset te visualiseren en analyseren. Een goede inleiding over LOWESS/LOESS is te vinden op aitechtrend.com. [1]
Hoewel de termen LOWESS en LOESS vaak door elkaar worden gebruikt, is er een klein verschil, vooral in R. LOWESS was de eerste implementatie, terwijl LOESS later kwam en flexibeler en krachtiger is. De loess() functie in R creëert een object met de resultaten, en de predict() functie haalt de geschatte waarden op.
In tegenstelling tot lineaire of polynomiale regressie, die een globale benadering over de gehele dataset toepassen, past LOESS lokale regressies toe op deelverzamelingen van de data. Dit leidt tot een vloeiendere curve die beter de variatie in de data volgt zonder aan te nemen dat er een specifieke vorm of structuur is.
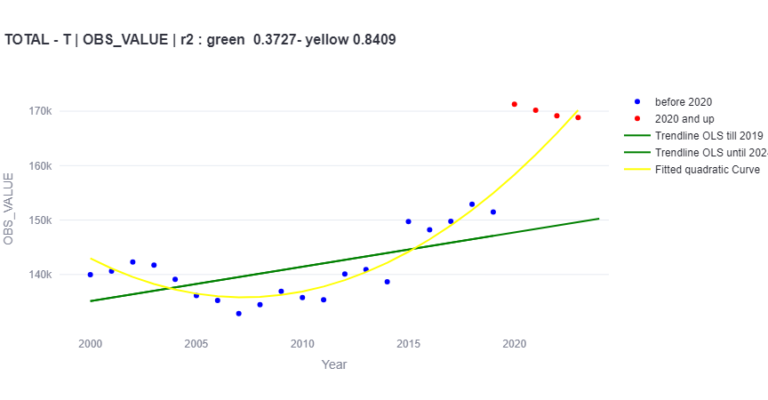
De trendlijn van LOESS kan worden gezien als een benadering van een 30-jarig gemiddelde en wordt vaak gebruikt in klimatologische analyses. Het is gebaseerd op lineaire lokale regressie, berekend met de statsmodels-bibliotheek, en gebruikt een bicubische gewichtsfunctie over een 42-jarig venster. In het centrale deel van de tijdreeks is de variantie van de trendlijnschatting ongeveer gelijk aan die van een 30-jarig gemiddelde.
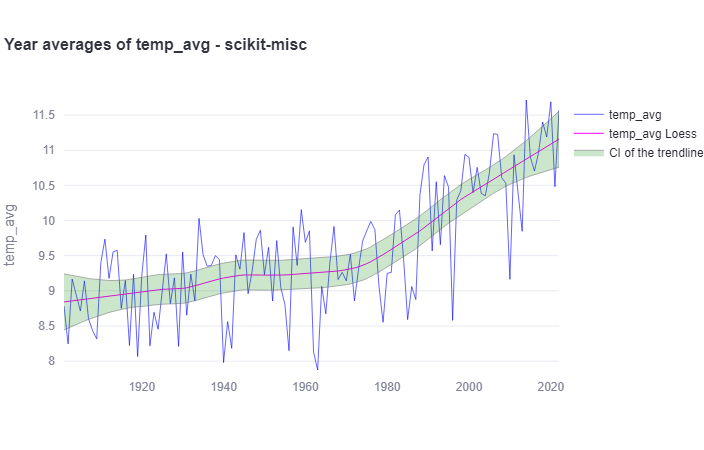
Keuze KNMI
Het KNMI heeft als standaardmethode gekozen voor lokale lineaire regressie (LOESS), om de volgende redenen:
- de trendlijn is een goede benadering van de trendlijn zoals berekend met het doorlopend 30 jaar gemiddelde, welke methode traditioneel voor klimatologische datareeksen gebruikt wordt;
- ten opzichte van het gewogen 30 jaar gemiddelde heeft het een belangrijk voordeel, namelijk dat ook een trendwaarde voor de eerste en de laatste 15 jaar van de datareeks berekend kan worden (wat bij een doorlopend 30 jarig gemiddelde niet het geval is);
- de trendwaarde voor een bepaald jaar kan na 21 jaar niet meer veranderen (in veel methodes, zoals lineaire regressie, verandert de hele trendlijn wanneer nieuwe data worden toegevoegd);
- de methode is niet op aannamen of arbitraire keuzes gebaseerd;
de methode kan worden toegepast op alle soorten weergegevens.
(KNMI/De Valk, 2020)[2]
Meer achtergronden en keuzes zijn te vinden in TR-389 [3], en verschillende vormen van LOESS in Python zijn te vinden op een interactive app [5]. Het is belangrijk om de juiste parameters te kiezen zoals hieronder aangegeven.
LOESS Integreren in Python met pandas
Om LOESS effectief te kunnen toepassen in Python, kunnen we gebruik maken van de `scikit-misc` bibliotheek. Deze bibliotheek biedt een robuuste implementatie van LOESS. We zullen een functie `loess_skmisc` definiëren en deze integreren met pandas zodat we eenvoudig LOESS-smoothing kunnen toepassen op pandas Series.
Stap 1: Definieer de `loess_skmisc` functie
Eerst definiëren we de `loess_skmisc` functie die de daadwerkelijke LOESS-berekeningen uitvoert. We plaatsen dit in een bestand genaamd utils.py
import numpy as np
from skmisc.loess import loess # Importeer loess van scikit-misc
import pandas as pd
def loess_skmisc(t, y, ybounds=None, it=1):
"""Make a plot with scikit-misc. Scikit-misc is the perfect reproduction of the method used by KNMI
See https://github.com/rcsmit/streamlit_scripts/blob/main/loess_scikitmisc.py for the complete version.
See https://github.com/rcsmit/streamlit_scripts/blob/main/loess.py for a comparison of the various methods.
Args:
t : list of time values, increasing by 1.
y : list of values
ybounds : list or array-like, optional
Lower/upper bound on the value range of y (default: [-Inf, Inf]).
it : number of iterations
Returns:
loess : list with the smoothed values
ll : lower bounds
ul : upper bounds
span = 42/len(y), wat de 30 jarig doorlopend gemiddelde benadert
https://www.knmi.nl/kennis-en-datacentrum/achtergrond/standaardmethode-voor-berekening-van-een-trend
KNMI Technical report TR-389 (see http://bibliotheek.knmi.nl/knmipubTR/TR389.pdf)
https://www.knmi.nl/kennis-en-datacentrum/achtergrond/standaardmethode-voor-berekening-van-een-trendhttps://www.knmi.nl/kennis-en-datacentrum/achtergrond/standaardmethode-voor-berekening-van-een-trend
"""
# https://has2k1.github.io/scikit-misc/stable/generated/skmisc.loess.loess.html
# https://stackoverflow.com/questions/31104565/confidence-interval-for-lowess-in-python
# Set default value for ybounds
if ybounds is None:
ybounds = [-np.inf, np.inf]
elif len(ybounds) != 2:
ybounds = [-np.inf, np.inf]
ybounds = sorted(ybounds)
# Dimensions and checks
t = np.asarray(t, dtype=np.float64)
y = np.asarray(y, dtype=np.float64)
dt = np.diff(t)[0]
n = len(y)
ig = ~np.isnan(y)
yg = y[ig]
tg = t[ig]
ng = sum(ig)
if ng <= 29:
raise ValueError("Insufficient valid data (less than 30 observations).")
# Check values of bounds
if np.any(yg < ybounds[0]) or np.any(yg > ybounds[1]):
raise ValueError("Stated bounds are not correct: y takes values beyond bounds.")
span = 42/len(y)
l = loess(t,y)
# MODEL and CONTROL. Essential for replicating the results from the R script.
#
# https://has2k1.github.io/scikit-misc/stable/generated/skmisc.loess.loess_model.html#skmisc.loess.loess_model
# https://has2k1.github.io/scikit-misc/stable/generated/skmisc.loess.loess_control.html#skmisc.loess.loess_control
l.model.span = span
l.model.degree = 1
l.control.iterations = it # must be 1 for replicating the R-script
l.control.surface = "direct"
l.control.statistics = "exact"
l.fit()
pred = l.predict(t, stderror=True)
conf = pred.confidence()
loess_values = pred.values
ll = conf.lower
ul = conf.upper
return t, loess_values, ll, ul
Stap 2: Maak een pandas accessor voor de LOESS-methode
Vervolgens registreren we een pandas accessor zodat we de `loess` methode direct kunnen toepassen op pandas Series objecten. Ook deze accessor plaatsen we in utils.py
# Define the pandas accessor
@pd.api.extensions.register_series_accessor("loess")
class LoessAccessor:
def __init__(self, pandas_obj):
self._obj = pandas_obj
def apply(self, ybounds=None, it=1):
t = np.arange(len(self._obj))
y = self._obj.values
_, loess_values, ll, ul = loess_skmisc(t, y, ybounds, it)
return loess_values
Stap 3: Gebruik de LOESS-methode in je DataFrame
We kunnen nu de LOESS-methode eenvoudig toepassen op een kolom in een pandas DataFrame:
import pandas as pd
import numpy as np
import plotly.graph_objects as go
import utils
url = "https://raw.githubusercontent.com/rcsmit/streamlit_scripts/main/input/de_bilt_jaargem_1901_2022.csv"
df = pd.read_csv(
url,
delimiter=",",
header= 0,
comment="#",
low_memory=False,
)
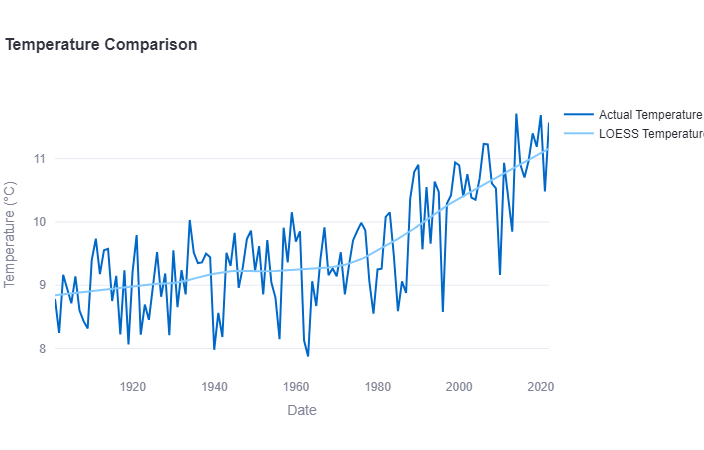
df['temp_avg_loess'] = df['temp_avg'].loess.apply()
fig = go.Figure()
# Add traces for temp_loess and temp
fig.add_trace(go.Scatter(x=df['YYYY'], y=df['temp_avg'], name='Actual Temperature'))
fig.add_trace(go.Scatter(x=df['YYYY'], y=df['temp_avg_loess'], mode='lines', name='LOESS Temperature'))
fig.update_layout(title='Temperature Comparison',
xaxis_title='Date',
yaxis_title='Temperature (°C)')
fig.show()
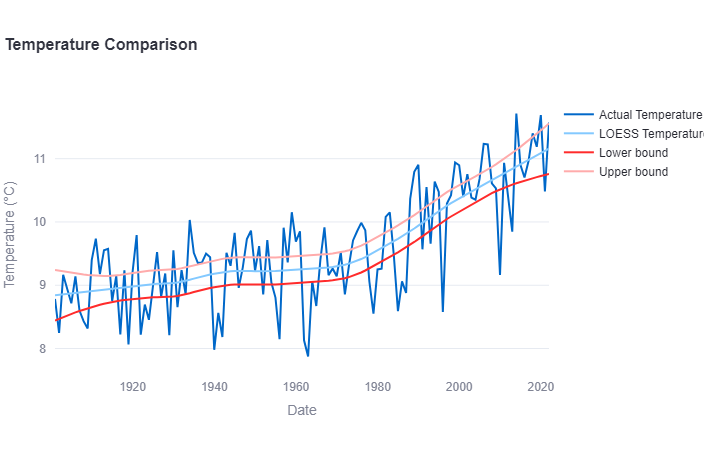
Stap 5: Gebruik de functie als normale functieaanroep
De functie kan ook gebruikt worden als normale functieaanroep. Hou er rekening mee dat het betrouwbaarheidsinterval gaat over de gevonden curve, niet over de meetwaardes.
import plotly.graph_objects as go
import pandas as pd
import utils
url = "https://raw.githubusercontent.com/rcsmit/streamlit_scripts/main/input/de_bilt_jaargem_1901_2022.csv"
df = pd.read_csv(
url,
delimiter=",",
header= 0,
comment="#",
low_memory=False,
)
X_array = df["YYYY"].values
Y_array = df["temp_avg"].values
t, loess_values, ll, ul = loess_skmisc(X_array, Y_array)
fig = go.Figure()
# Add traces for temp_loess and temp
fig.add_trace(go.Scatter(x=t, y=Y_array, name='Actual Temperature'))
fig.add_trace(go.Scatter(x=t, y=loess_values, mode='lines', name='LOESS Temperature'))
fig.add_trace(go.Scatter(x=t, y=ll, mode='lines', name='Lower bound'))
fig.add_trace(go.Scatter(x=t, y=ul, mode='lines', name='Upper bound'))
# Update layout
fig.update_layout(title='Temperature Comparison',
xaxis_title='Date',
yaxis_title='Temperature (°C)')
fig.show()
Conclusie
Door de LOESS-methode te integreren met pandas Series via een custom accessor, hebben we een flexibele en herbruikbare manier gecreëerd om LOESS-smoothing toe te passen op data. Dit maakt het eenvoudiger om trends en patronen in tijdreeksen en andere datasets te analyseren, terwijl de code georganiseerd en modulair blijft. Het gebruik van een aparte `utils.py` file zorgt voor een duidelijke scheiding van functionaliteit, wat bijdraagt aan de onderhoudbaarheid en herbruikbaarheid van de code.
Links
[1] AI Tech Trend. Smoothing Out the Noise: Analyzing Data with LOWESS Regression in Python bekeken 12 juni 2024
[2] KNMI. Standaardmethode voor berekening van een trend
[3] C.F. de Valk. Standard method for determining a climatological trend
KNMI number: TR-389, Year: 2020, Pages: 35



One Comment